Neural Network Application in Traffic Management
ProfessionalProject Repository
Paper Preview
Neural Network Application in Traffic Management
Introduction
This project explores how reinforcement learning can improve signal timing at a simulated four-way intersection. Instead of following a fixed cycle, the controller observes queue lengths, cumulative waits, the active phase, and the time spent in that phase before selecting the next signal action.
The system uses a Deep Q-Network trained over 1,000 episodes. Over time, the policy learns how to reduce congestion, lower waiting time, and make better use of green-light duration than a static controller.

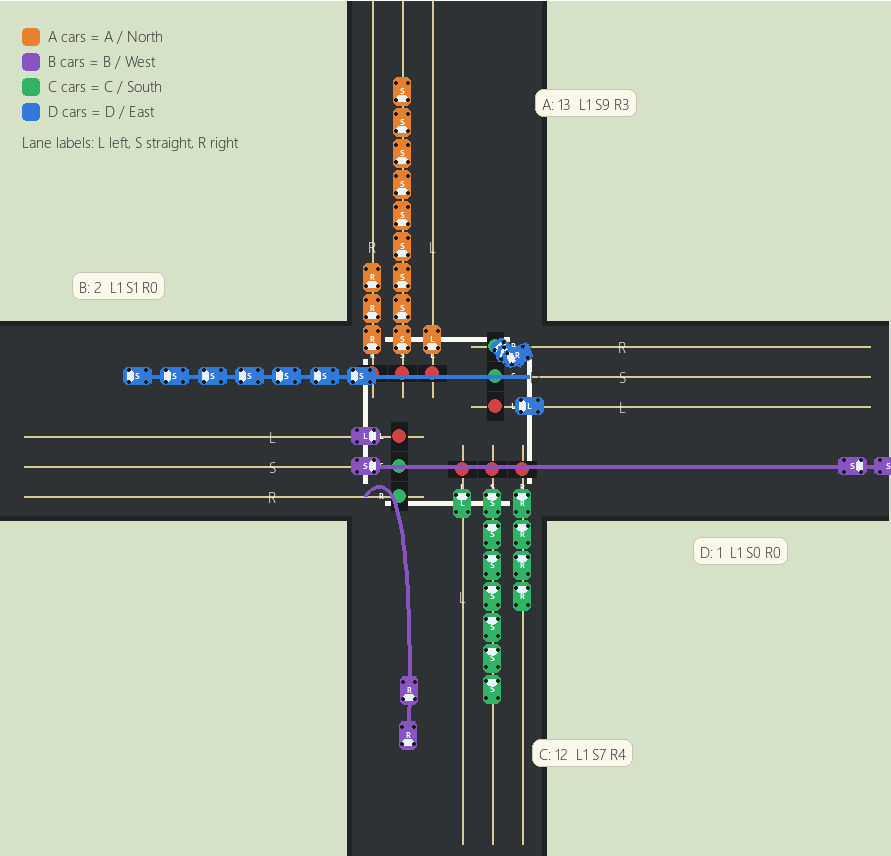
Traffic State Overview
System Architecture
The project is built around an environment model, a neural-network controller, and a simulation layer for testing and visualization. The environment represents a four-direction intersection with separate left, straight, and right lanes on each approach.
The agent receives a 27-dimensional state vector that combines per-lane queue information, accumulated waits, the current signal phase, elapsed phase time, and the previous duration. That state is used to estimate which phase-duration combination should be applied next.
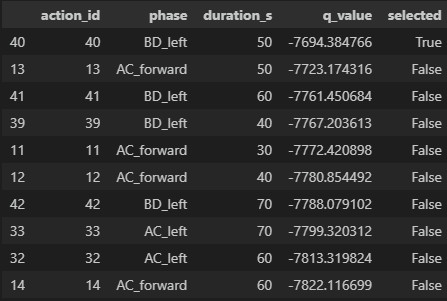
Model Output Selection
Learning and Control Design
The Deep Q-Network uses two hidden layers with ReLU activations. Its action space includes both the selected traffic phase and the selected green duration, allowing the model to learn timing decisions instead of only movement selection.
Training uses epsilon-greedy exploration, Adam optimization, and an experience replay buffer. The reward function encourages vehicle throughput while penalizing long waits, heavy queues, and inefficiently long green periods.
Visual Simulation
The project includes a live visualization tool that shows queue counts, active phases, and the model decision at each step. This makes it easier to inspect how the controller responds to changing traffic conditions and how those decisions affect the intersection state.
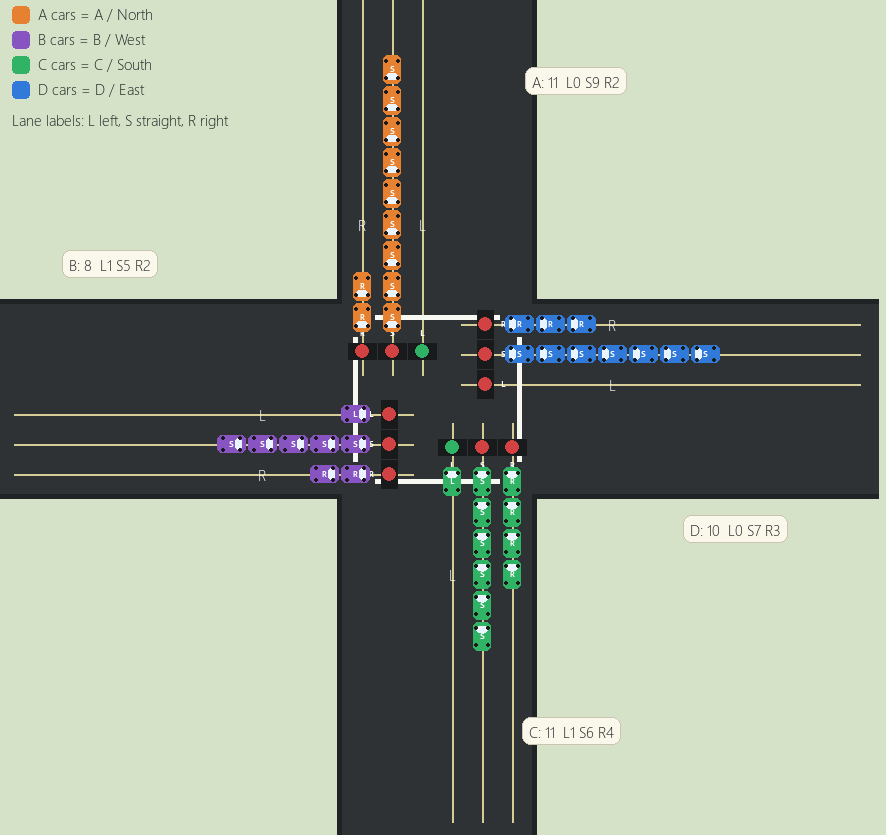
Intersection Visualizer
Decision State
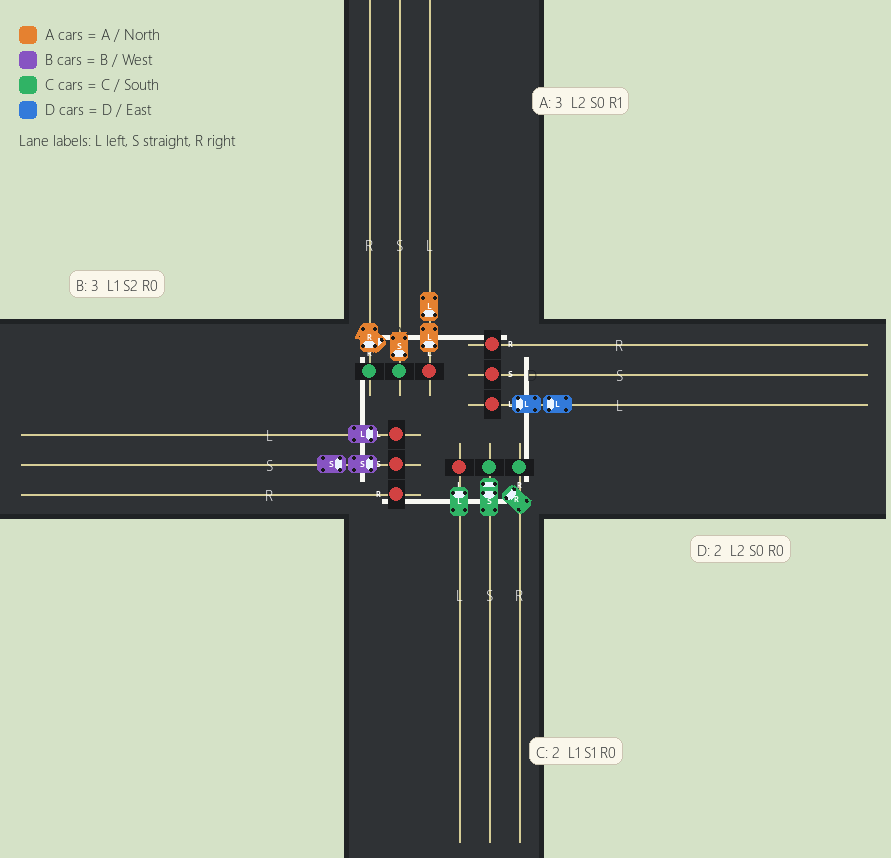
Post-Decision Result
Results
Training reward improved from roughly minus 3000 in the early episodes to under minus 900 by episode 1000. Even with high variance from random vehicle arrivals, the moving average shows a clear improvement in controller quality over time.
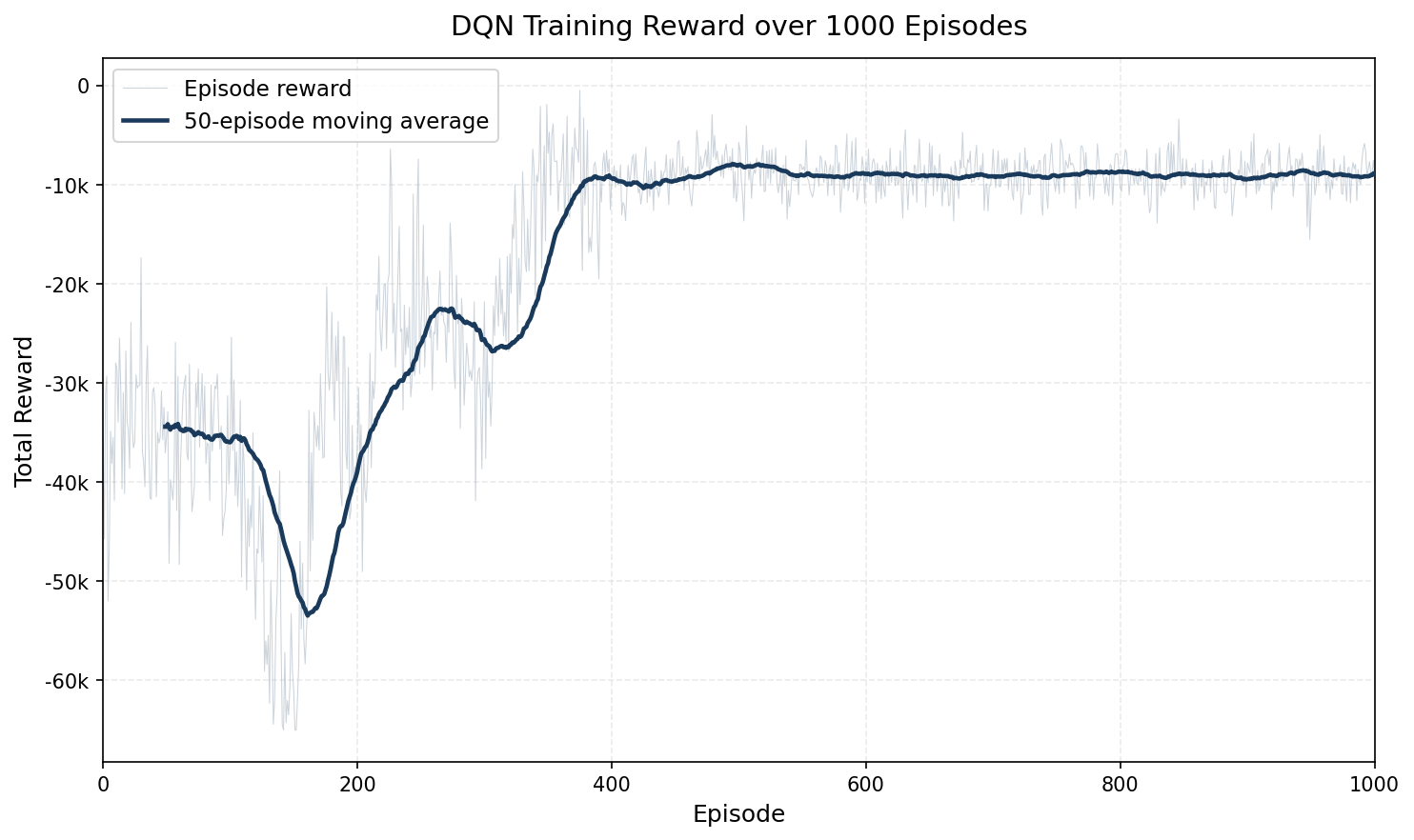
Training Reward Curve
The trained controller was then compared against fixed-time control, max-pressure control, and Webster's method. The DQN produced the best overall balance between keeping wait times low and limiting final queue growth, even when another baseline occasionally passed more total vehicles.
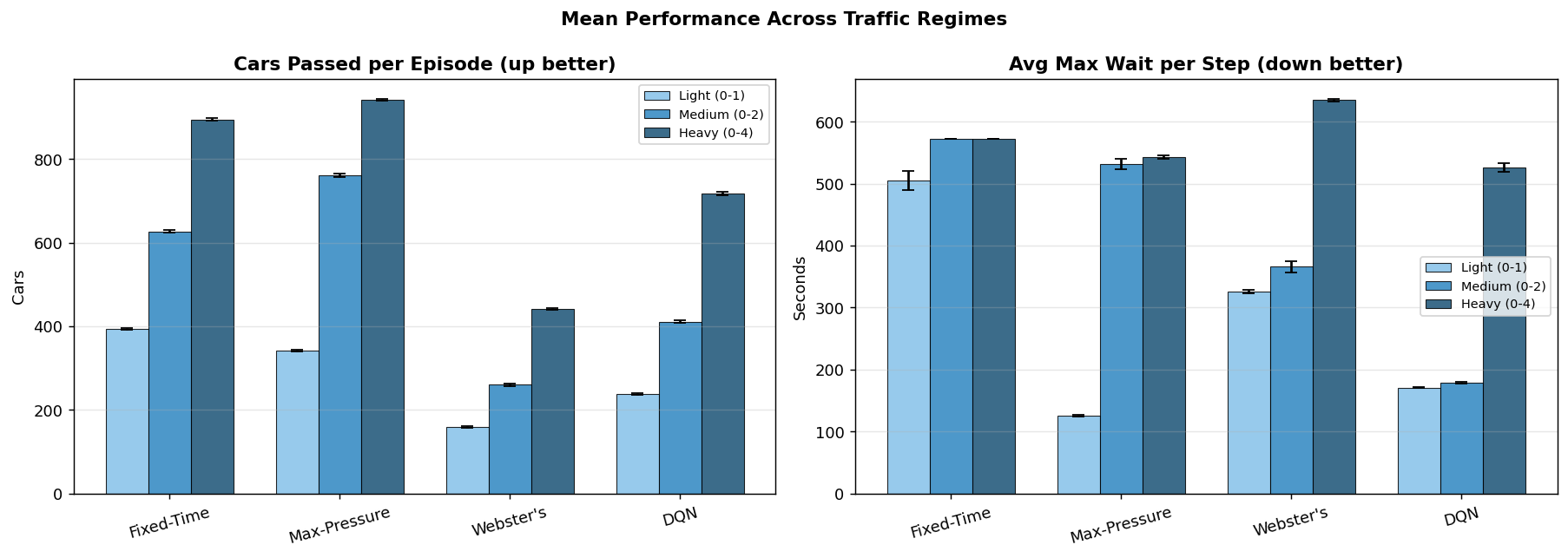
Traffic Regime Comparison
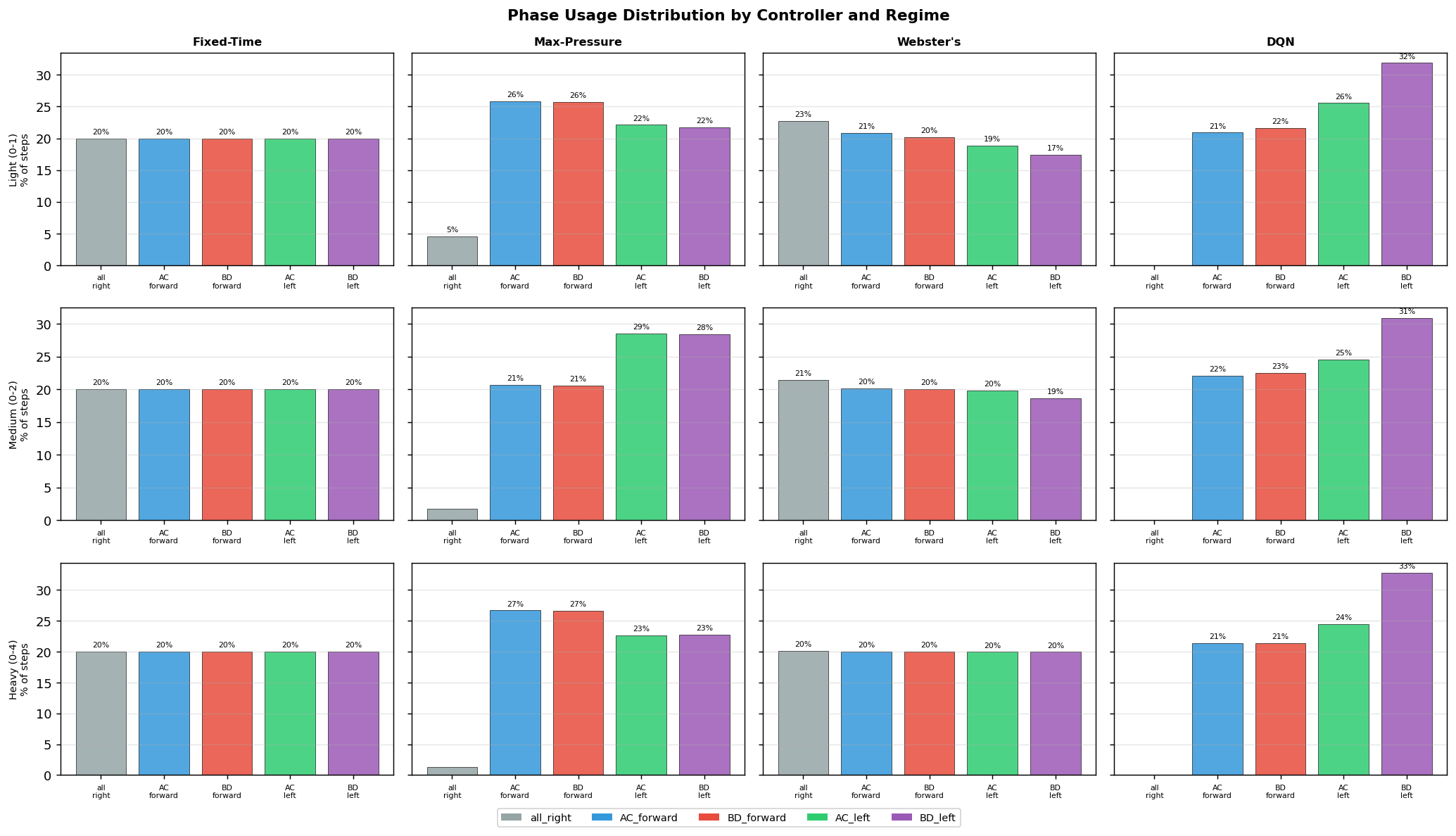
Phase Usage by Controller
Scenario Analysis
The controller was also tested on several targeted scenarios such as balanced traffic, directional surges, and left-turn-heavy conditions. These tests helped expose where the policy generalizes well and where it still struggles.
One of the main limitations appears in left-turn-heavy cases. Because the state representation does not always preserve enough lane-specific detail, the model can sometimes favor a through phase when a protected left turn would be more effective.
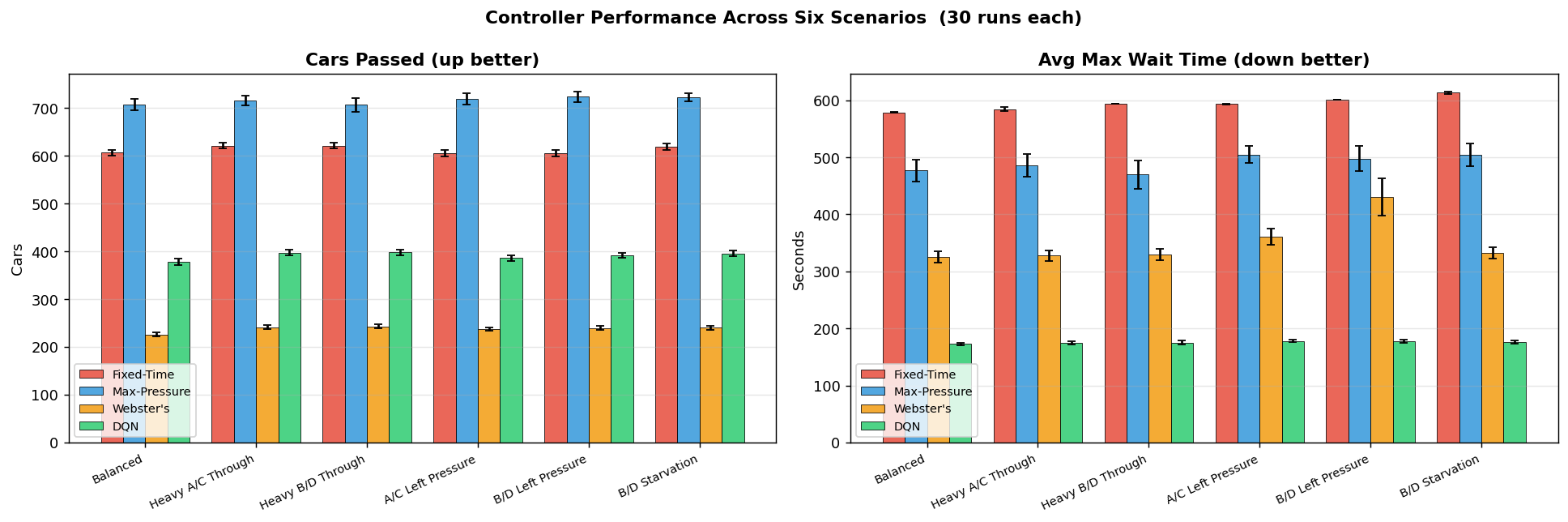
Controlled Scenario Results
Network-Level Generalization
To test generalization, the same trained policy was deployed across a connected 2 by 2 grid of intersections without retraining. Each node acted using only local information while still influencing neighboring intersections through propagated traffic flow.
This experiment showed that the single-intersection controller retained useful behavior beyond its original training setup while also revealing room for stronger network-level coordination.
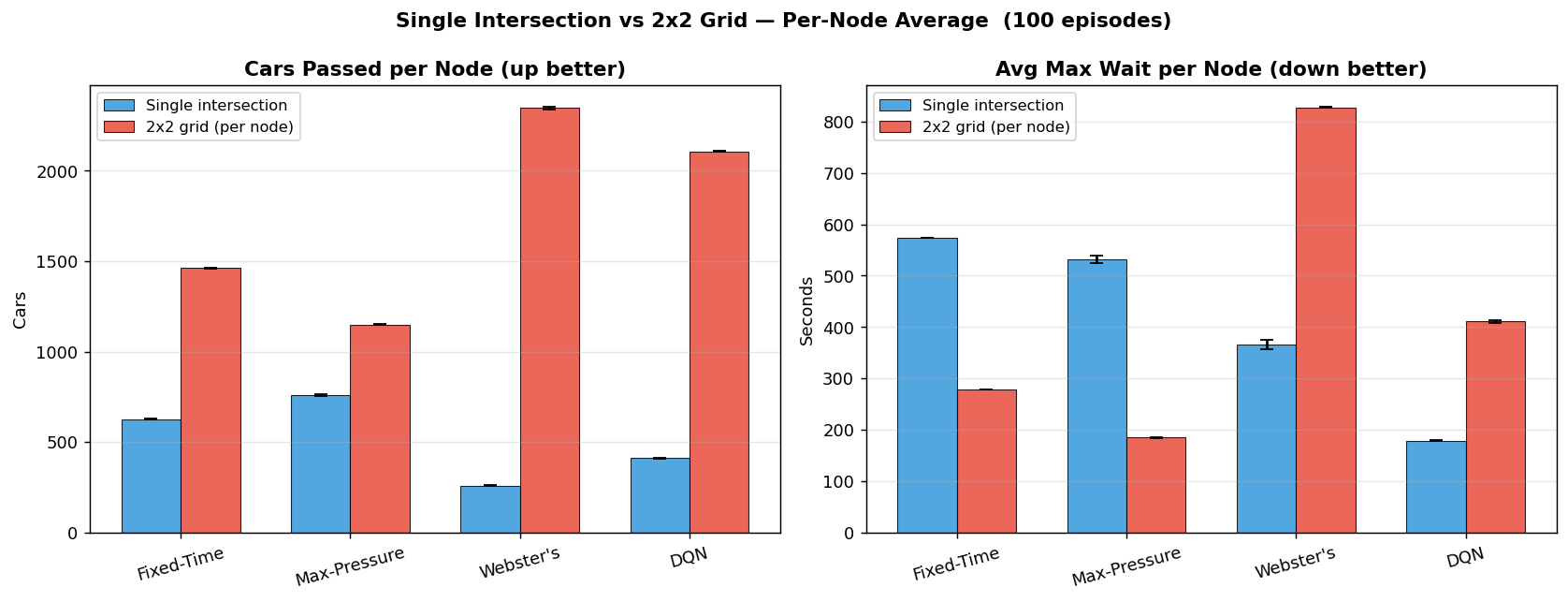
Grid Network Evaluation
Takeaways
This work shows that a compact DQN can learn an adaptive traffic-control policy that meaningfully reduces congestion and wait time in a simulated urban intersection. The most important next step is improving the state representation so turning behavior is preserved more explicitly at the lane level, especially for left-turn-heavy cases.
Project Gallery
.png)