Music Recommendation System
PersonalRelated Papers
Paper Preview
Music Recommendation System
Introduction
This project focused on building a music recommendation system under highly sparse training conditions. For each test user, the task was to rank 6 candidate tracks and predict exactly 3 as liked and 3 as disliked.
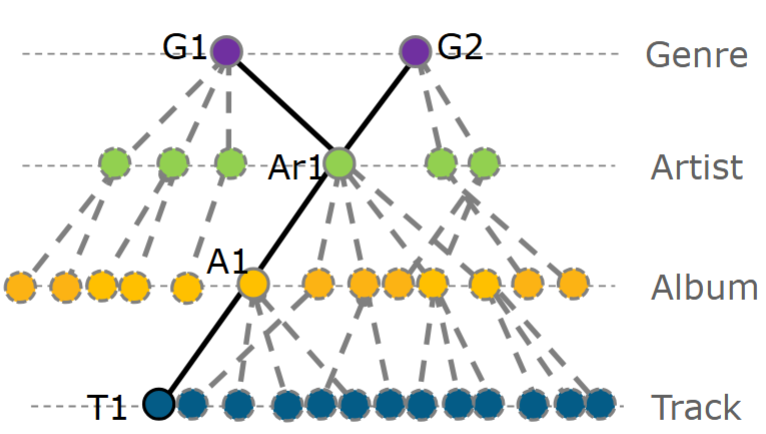
What made the problem more interesting than a standard track recommender was the data hierarchy. The dataset did not only expose tracks, but also albums, artists, and genres. That meant recommendation quality depended heavily on how well those relationships were exploited when direct track history was missing.
The project evolved from a heuristic ranking system into a broader experimentation pipeline that included Bayesian fallback logic, sibling-track reasoning, adaptive weighting, autoencoder-based fallback learning, collaborative filtering with ALS, Spark ML classifiers, and a final ensemble.
Music Recommendation System Overview
Goal and Problem
The goal was to predict user preference for unseen music tracks while using the available hierarchy as effectively as possible. In the training data, albums, artists, genres, and tracks all shared a flat ItemID namespace, so the recommendation system needed to infer taste across multiple entity types rather than treating everything as a direct track-only lookup problem.
The main challenge was sparsity. Many candidate tracks had no direct user interaction history, so the recommendation logic had to make informed decisions from indirect evidence such as:
- whether the user had rated the album
- whether the user had rated the artist
- whether the user had rated the track’s genres
- whether the user had rated sibling tracks from the same album
- what the global platform behavior suggested when personalized evidence was unavailable
Dataset Overview
The midterm report describes a large but sparse platform dataset with the following scale:
52,829albums18,674artists567genres224,041tracks12,403,575training ratings120,000test rows covering20,000users
Additional observations from the report:
- ratings ranged from
0to100 - the overall mean rating was about
49.77 - many tracks were missing album or artist IDs
- tracks could belong to multiple genres, with a mean of
2.44genres per track
This made the problem ideal for hierarchical fallback logic, because the recommendation system could rarely rely on one clean fully observed signal.
Core Heuristic Architecture
The first major phase of the project used a rule-based recommender built around the hierarchy:
Track -> Album -> Artist -> Genres
For each (user, track) pair, a feature vector was built using indirect preference signals:
album_scoreartist_scoregenre_countgenre_maxgenre_mingenre_meangenre_var
Each feature followed a three-level priority chain:
- the user’s own rating if available
- the global average or Bayesian-smoothed score for that item
- the overall dataset mean as a final cold-start fallback
This guaranteed that every user-track pair always had usable values, even when direct personalization was very limited.
Initial Scoring Strategies
Strategy 1: Weighted Hierarchical Average
The first main ranking rule emphasized the album as the strongest and most specific signal:
score_1 = 0.40 * album_score
+ 0.30 * artist_score
+ 0.30 * genre_mean
This strategy assumed that if a user strongly liked an album, tracks from that album were especially strong candidates. Artist and genre served as supporting evidence rather than the main driver.
Result:
- Kaggle score:
0.759
Strategy 2: Maximum Genre Score
The second strategy tested whether the user’s strongest single genre might be a better gateway signal:
score_2 = 0.70 * genre_max
+ 0.20 * artist_score
+ 0.10 * album_score
The intuition was that a user does not need to love every genre in a track to enjoy it. In practice, though, genre turned out to be too broad and noisy to serve as the main ranking driver.
Result:
- Kaggle score:
0.704
This early comparison established one of the most important conclusions of the project: album-level preference was much more predictive than broad genre affinity.
Cold-Start and Fallback Improvements
Bayesian Global Fallback
The mid-project report showed that a large share of lookups were falling back to a flat default score. To make those cases more meaningful, the fallback was upgraded to a Bayesian-smoothed global popularity score:
mu_hat_i = (N_i * r_bar_i + C * M) / (N_i + C)
where:
N_iis the item’s rating countr_bar_iis its raw average ratingCis the confidence thresholdMis the overall dataset mean
This reduced the bias from rarely rated items with extreme values and produced a much stronger global prior than a constant mean.
Dig Deeper Album-Sibling Logic
Another important improvement was the sibling-track rule. If a user had never rated the album directly, the system checked whether they had rated other tracks from the same album. If so, those sibling-track ratings were averaged and used as a proxy album score before falling back to global popularity.
This made the recommender more personalized without abandoning the heuristic structure.
Reported results after adding Bayesian fallback and sibling-track logic:
- Weighted Average + Bayesian + Dig Deeper:
0.774 - Max Genre + Bayesian + Dig Deeper:
0.708
The improvement was real, but the reports also showed that the dataset remained dominated by cold-start conditions, which limited how far purely heuristic rules could go.
Adaptive Weight Normalization
The next refinement was to stop blending weak fallback values with strong real user signals. Instead of always combining album, artist, and genre values, the model used only the hierarchy levels that the user had actually rated and then renormalized the weights.
Example intuition:
If only album has a direct rating:
score = 0.5 * album_score
weight = 0.5
final = score / weight = album_score
This prevented strong evidence from being diluted by generic fallback estimates.
Result:
- Adaptive Weight Normalization score:
0.792
This was a meaningful step because it made the system more deterministic, more personalized, and more faithful to the actual known user data.
Autoencoder Fallback
One of the most interesting ideas in the project was to keep the heuristic recommender intact, but replace only its weakest last-resort fallback with a learned model.
Instead of using deep learning as a full end-to-end recommender, the autoencoder was used only when:
- there was no direct album signal
- sibling-track inference failed
- the heuristic pipeline would otherwise fall back to a weak global prior
This preserved the logic and interpretability of the rule-based architecture while adding a more personalized learned estimate to the sparsest cases.
Result:
- Autoencoder fallback score:
0.849
This was a large jump over the earlier heuristic variants and showed that learned fallback logic can be especially effective when the rest of the hierarchy-based system is already strong.
Additional Modeling Experiments
The final report expanded beyond the heuristic core and tested several other recommendation families.
ALS and Multi-ALS
Collaborative filtering was explored through ALS models at the track, album, artist, and genre levels, followed by blending strategies.
Reported results:
- raw multi-ALS blend:
0.653 - rank blend:
0.646 - normalized blend:
0.688
These methods were useful for understanding latent factor modeling, but they did not outperform the hierarchy-aware hybrid methods.
Spark ML Classifiers
The project also tested supervised classifiers in Spark ML to predict preference directly:
- Decision Tree:
0.892 - Logistic Regression:
0.910 - Gradient Boosted Trees:
0.915 - Random Forest:
0.918
These results were notably strong and showed that once the ranking problem is expressed in a supervised-learning-friendly way, classical tree-based models can perform very well.
Final Ensemble
After accumulating dozens of experiments and Kaggle submissions, the final stage combined many of the strongest approaches into a weighted ensemble.
The ensemble logic:
- gathered multiple prior submission vectors
- normalized predictions into a common scale
- treated each submission as a solution vector
- estimated weights from known Kaggle performance
- combined them into a final ranking score
This became the best-performing approach in the project.
Result:
- Ensemble score:
0.921
Results Summary
The final report’s ranked outcomes were:
- Ensembling Logic:
0.921 - Random Forest:
0.918 - Gradient Boosted Trees:
0.915 - Logistic Regression:
0.910 - Decision Tree:
0.892 - Autoencoder Fallback:
0.849 - Adaptive Weight Normalization:
0.792 - Weighted Average + Bayesian + Dig Deeper:
0.774 - Weighted Hierarchical Average:
0.759 - Max Genre + Bayesian + Dig Deeper:
0.708 - Maximum Genre Strategy:
0.704 - normalized blend:
0.688 - raw multi-ALS blend:
0.653 - rank blend:
0.646
Architecture Summary
By the end of the project, the system had evolved into a layered recommendation architecture:
- hierarchical feature extraction from album, artist, and genre relationships
- personalized heuristic scoring using direct and indirect user history
- Bayesian fallback for cold-start robustness
- sibling-track reasoning for album inference
- adaptive normalization to avoid diluting strong signals
- learned fallback through an autoencoder
- comparison models through ALS and Spark ML
- ensemble integration across top-performing submissions
Key Takeaways
The strongest lesson from the project is that a good recommender does not come from blindly choosing the most complex model. The best performance came from understanding the structure of the data, identifying the weakest parts of the pipeline, and applying the right method at the right stage.
In this dataset:
- album-level preference was the strongest single signal
- genre-based methods were too broad to drive ranking well on their own
- fallback quality mattered far more than it initially seemed
- hybrid systems outperformed single-method thinking
- ensembling multiple strong but different models produced the best final result
Closing Reflection
This project is a strong example of iterative recommendation-system design. It started with interpretable heuristics, used analysis to expose bottlenecks, introduced more informed fallbacks, experimented with learned models only where they were most useful, and finished with an ensemble that integrated the strengths of the entire exploration process.
Project Gallery