Detecting AI-Generated Images Through Spatial-Frequency Analysis and Diffusion-Based Reconstruction
ProfessionalRelated Papers
Project Repository
Paper Preview
Detecting AI-Generated Images Through Spatial-Frequency Analysis and Diffusion-Based Reconstruction
Introduction
This project investigates whether AI-generated images can be separated from real photographs using the image content itself rather than relying on metadata, watermarks, or hidden tags. That distinction matters because common labeling methods are easy to remove through screenshotting, compression, or cropping.
The core idea is that generated images are produced from learned statistical distributions, while real photographs are shaped by physical processes such as lighting, optics, sensor noise, and scene geometry. Even when the images look visually similar, those different origins can leave measurable differences in how pixels are arranged.
To test that hypothesis, the project explores two complementary detection strategies:
- a hybrid spatial-frequency classifier that combines learned visual features with FFT-based descriptors
- a diffusion-based reconstruction method that measures how well a diffusion model restores corrupted images
Hybrid Classifier Results
Dataset and Problem Setup
The hybrid classifier was trained on a dataset of 1,965 images split into training, validation, and test sets with a 70, 20, and 10 ratio. The dataset includes people, nature, cities, animals, and art so the model does not simply learn one content category instead of the difference between real and generated imagery.
The diffusion experiments used a second dataset made of three small groups:
- native AI images generated by Stable Diffusion v1.5
- cross-model AI images generated by other models
- real photographs
This separation made it possible to compare how reconstruction changes depending on whether the image belongs to the diffusion model's own training distribution or to a different source.
Methodology 1: Hybrid Spatial-Frequency Classifier
The first method combines a pretrained ResNet50 backbone with handcrafted FFT statistics. The ResNet branch captures semantic and textural structure such as edges, shapes, and patterns, while the frequency branch looks for spectral artifacts, periodicity, and unnatural regularity that may appear in generated images.
Instead of feeding the full FFT spectrum into the classifier, the system extracts a compact set of statistical descriptors, including:
- mean magnitude
- standard deviation of magnitude
- high-frequency energy
- high-to-low frequency ratio
- spectral entropy
- radial variance
Those FFT features are passed through a small multilayer perceptron and then concatenated with the ResNet feature vector before reaching the final classification head.
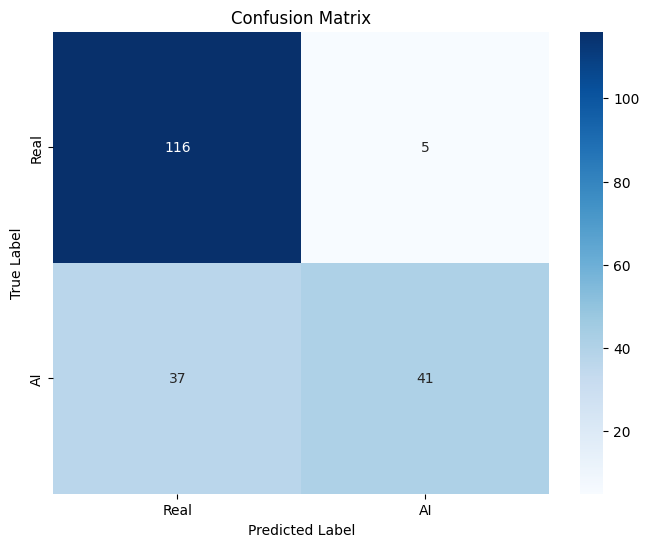
Classification Results
The best-performing version used 256 by 256 input images and achieved the following test performance:
- accuracy of 78.89 percent
- precision of 89.13 percent
- recall of 52.56 percent
- F1 score of 66.13 percent
The model showed strong precision, meaning that when it predicted an image was AI-generated it was often correct. The bigger weakness was recall, since many generated images were still misclassified as real.

FFT Examples for Real Images
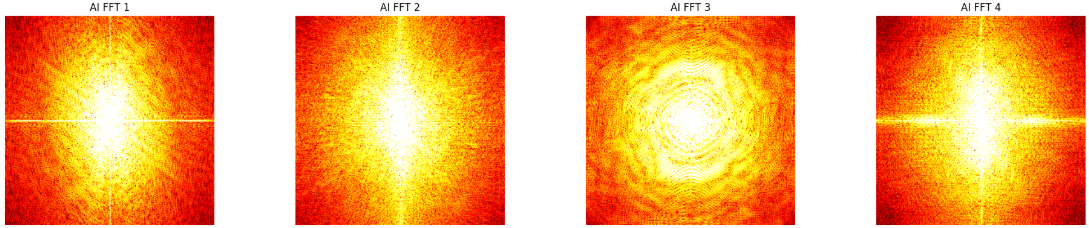
FFT Examples for AI Images
The FFT visualizations help show the intuition behind the method. Real-image spectra often look softer and more diffuse, while AI-generated examples tend to show sharper vertical and horizontal lines, stronger rings, or more explicit periodic structure.
Methodology 2: Diffusion-Based Reconstruction
The second method asks a different question: if a diffusion model is asked to repair a damaged image, does it reconstruct images from its own learned distribution more effectively than real photographs
To test that, gaussian noise was injected into the top-left quadrant of each image, and Stable Diffusion v1.5 was used to denoise the result. Reconstruction quality was then measured with structural similarity metrics instead of a direct classifier.
This pipeline used:
- Stable Diffusion v1.5
- a VAE for image-to-latent conversion
- a UNet denoiser
- CLIP text components
- a DDIM scheduler for diffusion timesteps
Reconstruction Results
Attempt 1: Full-Image Denoising
In the first attempt, the noisy image was denoised globally and reconstruction quality was measured on the full image. This worked well as a detection signal.
Native AI images reconstructed best, cross-model AI images came next, and real photographs reconstructed the worst. That result supports the main hypothesis: a diffusion model can better recover imagery that is statistically closer to its own learned distribution.

Native AI Reconstruction

Cross-Model AI Reconstruction

Real Image Reconstruction
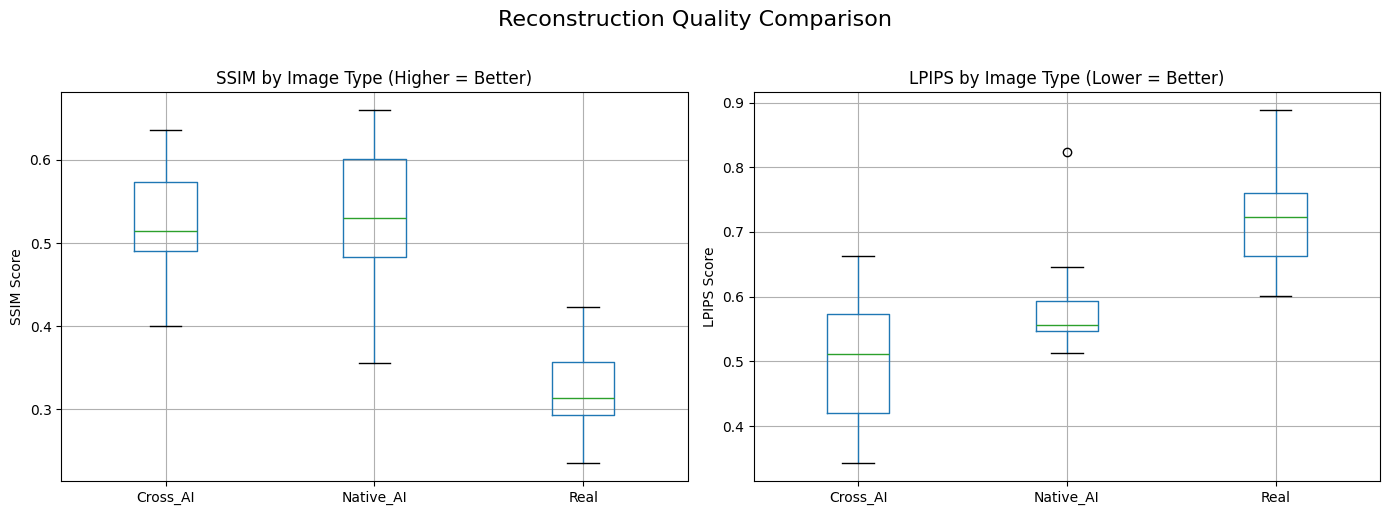
Attempt 1 Metric Distribution
One of the most interesting outcomes is qualitative rather than purely numeric. When repairing AI-generated images, the diffusion model often preserves the original semantic content convincingly. With real photographs, it more often simplifies or misinterprets details, treating some natural image structure as noise.
Attempt 2: Selective Denoising
The second attempt overlaid only the repaired noisy quadrant back onto the clean original image and evaluated similarity on that local region alone. While reconstruction scores became higher overall, this setup did not separate the classes effectively.
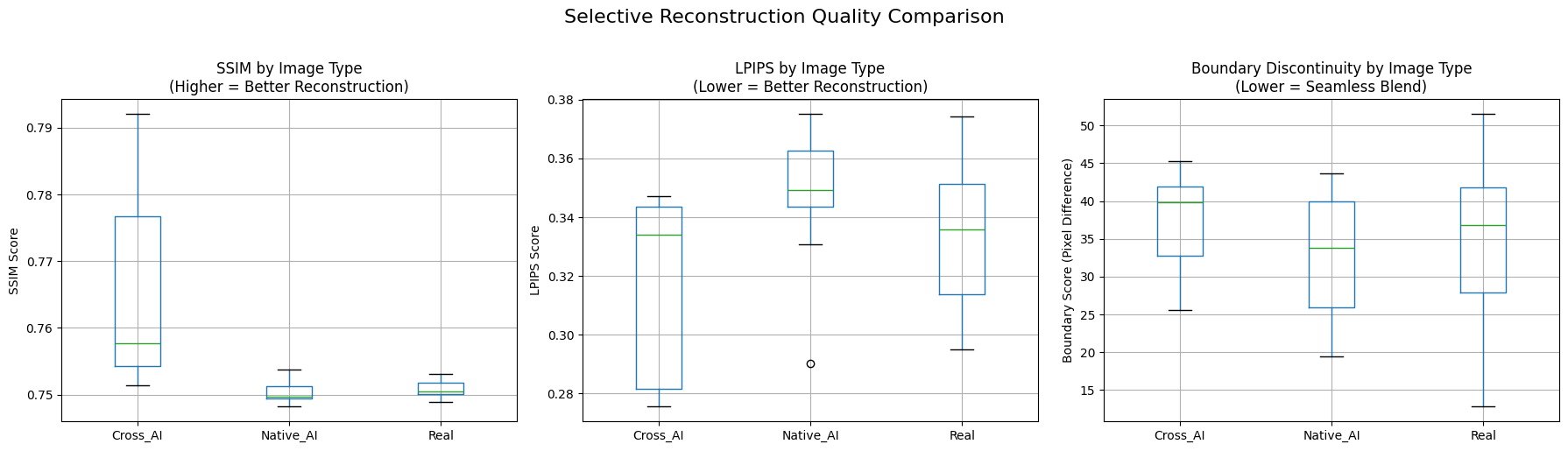
Selective Denoising Results
This failure was still informative. The task became too local and too easy because most of the image stayed untouched, giving the model strong context during denoising. That made global reconstruction analysis much more meaningful than local patch restoration for this use case.
Findings
Together, the two approaches support the idea that AI-generated images do carry detectable signals, but those signals depend heavily on scale, framing, and implementation choices.
The hybrid classifier demonstrated that supervised detection is viable, especially when semantic features and spectral cues are combined. The diffusion experiments added a second perspective by showing that reconstruction quality itself can reflect whether an image aligns with a diffusion model's learned distribution.
Across the broader experimentation, several patterns stood out:
- simpler baselines often generalized better on the small dataset
- global analysis was more useful than local patch analysis
- image resolution strongly affected FFT usefulness and classifier behavior
- overfitting and generalization were the main performance bottlenecks
Limitations and Next Steps
There are still several important constraints in the current version of the project:
- AI recall remains relatively low, so too many generated images are still missed
- the dataset is small for a deep learning problem and showed rapid overfitting
- the FFT descriptors are broad and could be made more targeted or multi-scale
- diffusion testing was limited in iterations, noise strength, and prompt usage
- resizing different source image sizes may have removed useful information
- additional backbones such as ResNet18 or EfficientNet should be explored
Overall, this project shows that content-based AI-image detection is feasible, but robust real-world performance will likely require stronger generalization, richer frequency analysis, and larger, more diverse datasets.
Project Gallery